私域运营微信群
扫码进群,与国内数万私域运营人员一起交流,定时分享前沿、专业、深度的私域营销方案。
搜索
扫码进群,与国内数万私域运营人员一起交流,定时分享前沿、专业、深度的私域营销方案。
| |

继520后,又一个大型示爱节点七夕到了。作为传统节日,七夕的爱情属性更为纯粹鲜明,

本期亮点功能 第244期更新 视频号小店打通推三返一和X+1活动【新增】; 汇付分账优

2023年伊始,私域运营已逐渐成为众多企业战略层面的关注焦点。无论是由于疫情导致线下

启博微分销智慧门店新零售解决方案:数字化连锁门店助力线上营销创新 随着消费者购物

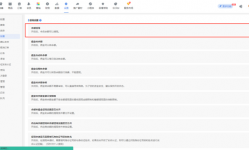
私域运营是指在不依赖公域流量的情况下,通过社交媒介与客户进行沟通和引导,最终实现

线下门店做分销,实际是新零售环境下一种有效联动线上线下流量、销量的营销方式。对于

本文将分享小程序商城的两个方法,帮助商家积累数万私域客户。 ·第一招是推出付费金

本期亮点功能 第231期更新 1.门店后台创建订单可选配送方式【新增】; 2.供应商创建

从腾讯2022年Q3财报中看到,微信小程序的日活已破6亿,是实现私域增长的核心引擎,小

开工大吉 启博2023乔迁新址:浙江省杭州市余杭区利尔达园区1幢7楼 新年新貌新风采 万
关注0
粉丝1
帖子560







声明:本站内容由网友分享或转载自互联网公开发布的内容,如有侵权请反馈到邮箱 1415941@qq.com,我们会在3个工作日内删除,加急删除请添加站长微信:15924191378
Copyright @ 2022-2024 私域运营网 https://www.yunliebian.com/siyu/ Powered by Discuz! 浙ICP备19021937号-4